What Is Data Engineering?
Data engineering has evolved from slow, brittle pipelines to real-time intelligent systems that power modern AI. This story reveals how lakehouse architectures and streaming platforms are transforming industries.
5/8/20242 min read
Data engineering has transformed more in the last five years than in the previous twenty. We have moved from:
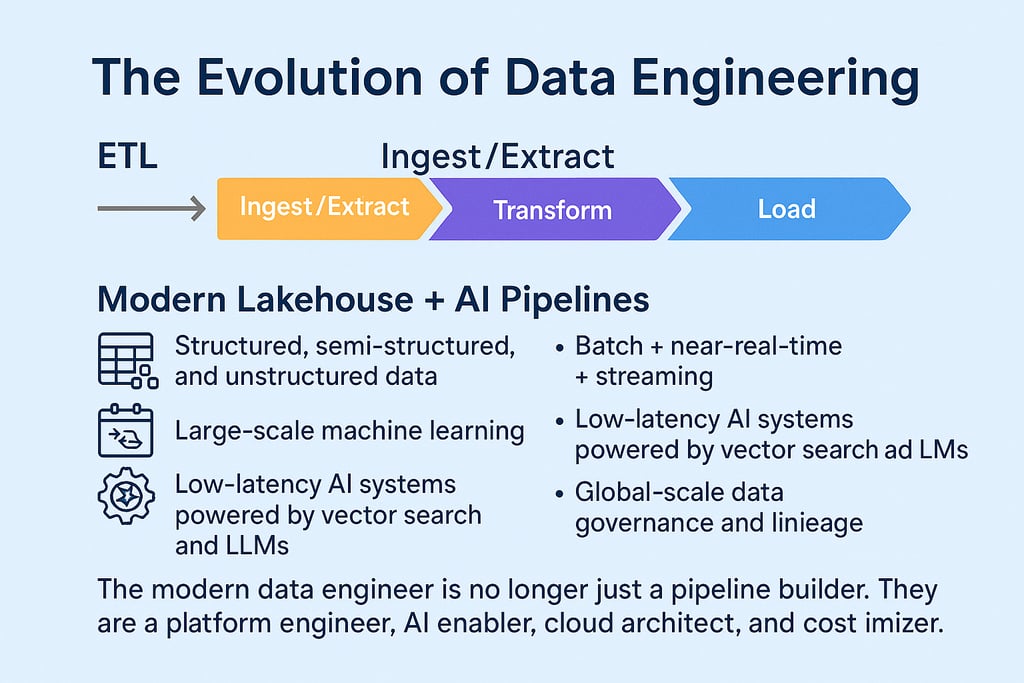
ETL (Ingest/Extract → Transform → Load)
ELT (Ingest/Extract → Load → Transform)
Modern Lakehouse + AI Pipelines
Over the last 18 years, I’ve watched data engineering continually evolve as data itself transformed—from Excel files to traditional data warehouses, to data lakes, and ultimately the modern lakehouse. Today’s platforms must support:
Structured, semi-structured, and unstructured data
Batch + near-real-time + streaming
Large-scale machine learning
Low-latency AI systems powered by vector search and LLMs
Global-scale data governance and lineage
Traditional pipelines operated at weekly, daily or hourly granularity whereas modern pipelines operate at:
Milliseconds (Kafka, Kinesis, Pub/Sub)
Real-time streaming (Flink, Spark Structured Streaming)
Micro-batch (Databricks Delta Live, Snowflake Pipe/Stream)
The modern data engineer is no longer just a pipeline builder. They are a platform engineer, AI enabler, cloud architect, and cost optimizer.
From 4-day ETL Failures → AI-driven Lakehouse Success:
Twelve years ago, a retail company struggled with a legacy data warehouse:
Queries took hours
Pipelines failed every week
A single batch load ran four days
Reporting was next-day, not real-time
Customer behavior was shifting online, but the tech stack couldn’t keep up.
So the company embraced the lakehouse paradigm:
Ingesting clickstreams
Capturing app events
Streaming real-time inventory
Using Delta Lake for reliability
Deploying models with MLflow
Today, the same company uses an AI-driven lakehouse where:
ML models predict demand
Automated pipelines power decisions in real time
Personalized recommendations update instantly
This transformation was not just technical—it changed the business.
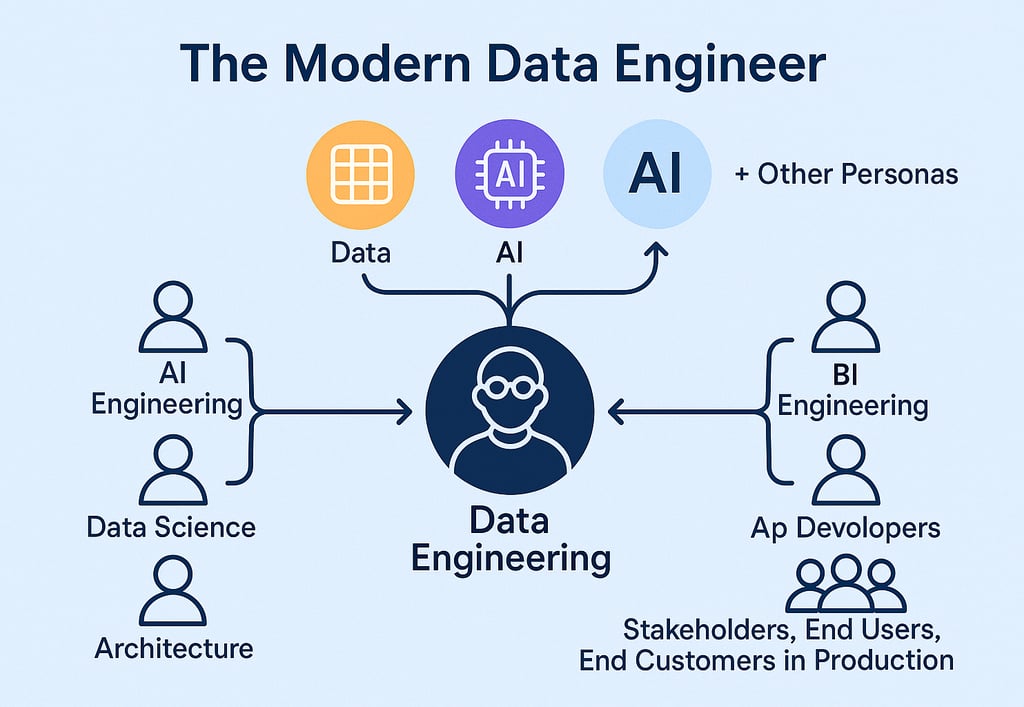
Why AI is Redefining Data Engineering
LLMs and GenAI now require:
vector databases
embedding generation
retrieval-augmented generation (RAG)
real-time feature engineering
high-quality training datasets
And all of these responsibilities fall on the data engineering team.
The lakehouse is no longer just a storage and compute platform. It is the foundation for AI.
Data engineering is entering its most exciting era:
AI-native architectures
Real-time decisioning
Unified governance & lineage
Massive scale and low latency
LLM-powered data products
And this is only the beginning.
If the last five years reinvented data engineering, the next five will be defined by autonomous pipelines, intelligent agents, and predictive automation built directly on the lakehouse. Engineers who master platforms like Databricks and Snowflake will be uniquely positioned to lead this transformation. Data engineering isn’t just evolving. It’s accelerating. And those who adapt now will shape the next generation of AI-driven enterprises.